Tools





ANOVA
Models
Regression by Backwards Elimination
Data Transforms
Transformations used in Regression
F Statistic
The F statistic calculation is used in a test on the hypothesis that the ratio of a pair of mean squares is at least unity (i.e. the mean squares are identical). Ordinarily the F statistic calculation is used to verify the significance of the regression and of the lack of fit.
In a regression analysis, the F statistic calculation is used in the ANOVA table to compare the variability accounted for by the regression model with the remaining variation due to error in the model (i.e. the model residuals). The null hypothesis of the test is that the coefficients of the regression model are zero; the alternative hypothesis is that at least on e of the coefficients is non-zero (thus providing some ability to estimate the response).
Statistical software like our SPC software will usually directly report the p-value (i.e. level of significance) of the F statistic. In most analyses, a p-value of 0.05 or less is considered sufficient to reject the hypothesis that the coefficients are zero; in other words, when the p value is less than 0.10, the regression model may be worthy of further analysis. Note that a p- value of 0.10 may be used as the threshold for preliminary investigations (with limited data).
![]()
where the mean square regression is MSreg = SSreg = Β1Sxy. Note: The degrees of freedom for the regression = 1, and the mean square error (residual) is
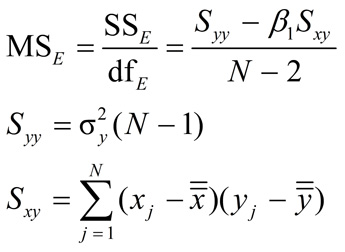
where N is the total number of observations,
![]() and
and
![]() are the averages of x and y, respectively, and σ y is the sample sigma of the y values.
are the averages of x and y, respectively, and σ y is the sample sigma of the y values.
Learn more about the Regression tools in Six Sigma Demystified (2011, McGraw-Hill) by Paul Keller, in his online Regression short course (only $99), or his online Black Belt certification training course ($875).
